Designing E-Learning 3.0 in gRSShopper - 8
E-Learning 3.0 - Part 1 - Part 2 - Part 3 - Part 4 - Part 5 - Part 6 - Part 7 - Part 8 - Part 9 - Part 10 - Part 11 - Part 12 - Part 13
Syndication
Syndication is the core of the cMOOC approach to learning and we haven't talked about it at all yet. It's pretty easy to get caught up in things like video events and content and to forget that the true purpose of the course is connection.
OPML
Now that we have a list of feeds (even if we haven't started harvesting them) we can make this list available to other people. Of course we've done that with the Your Feeds page, but that page is designed for humans.
What we want is to enable other feed readers (including other instances of gRSShopper) to automatically load a list of feeds and start harvesting them with a minimum of work.This is what OPML provides. It's a standardized data format created by Dave Winer as an outliner, and it works really well and is widely used for this purpose. Here's some information about it: https://en.wikipedia.org/wiki/OPML
So we need to create an OPML file.
I could use a Perl Module to create the OPML file. The advantage is that it will do all my error-checking for me. The disadvantage is that it means installing yet another Perl module. And I still have to write a bunch of script around it to make it work. That's how most software works (and why things like Moodle and WordPress have so many plugins). I'm not a fan of a new plug-in for every data type.
And besides, it's not hard to create OPML files with gRSShopper as it is.
Let's make a page we'll call course_opml.xml and have it display a list of feeds.
 |
| Figure 102 - Feeds OPML page in the Page Editor |
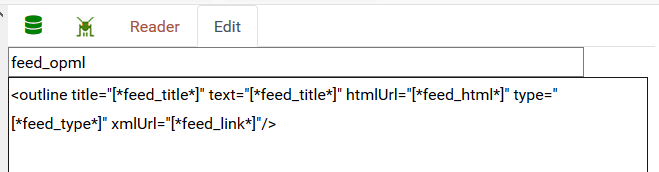 | ||
| Figure 103 - feed_opml view in the View Editor |
Now we'll give the page a header and footer. I could use boxes or templates, but I decided to just bake them right into the page, since I'll only ever have one OPML page. Here they are, copied and pasted directly from Dave Winer's example:
 |
| Figure 104 - OPML header and footer copied from Dave Winer |
Now I'll edit them for our purposes.
 |
| Figure 105 - OPML page in the page editor, edited |
Three things:
First, note the encoding in the first line. I've changed that from ISO-8859-1 to UTF-8. This is necessary because I have international characters in my feed names, and ISO-8859-1 is the Latin1 character set, while UTF-8 is international.
Second, note the date command: date format=rfc822
OPML and RSS files require dates in the RFC822 format (which is a pain). gRSShopper supports a number of different date formats, including RFC822.
Here's the full list:
epoch 1537131026
nice Sept 16, 2018
niceh Sept 16, 2018 4:50 p.m.
time 16:50
rfc822 16 Sept 2018 16:50:00 -0400
tzdate 2018/09/16
datepicker 2018/09/16 16:50
ics 20180916T165000
iso 2018-9-16
isoh 2018-09-16T16:50:00
Third, there are some special characters in there, and XML doesn't like special characters. gRSShopper escapes special characters, but it needs to know the page is XML. I realize that I need to add the page_type Optlist to the page form.
Here's the page_type Optlist (it was already included in gRSShopper; I didn't have to create this):
 |
| Figure 106 - post_type in the Optlist Eitor |
and here's the Form Editor for page
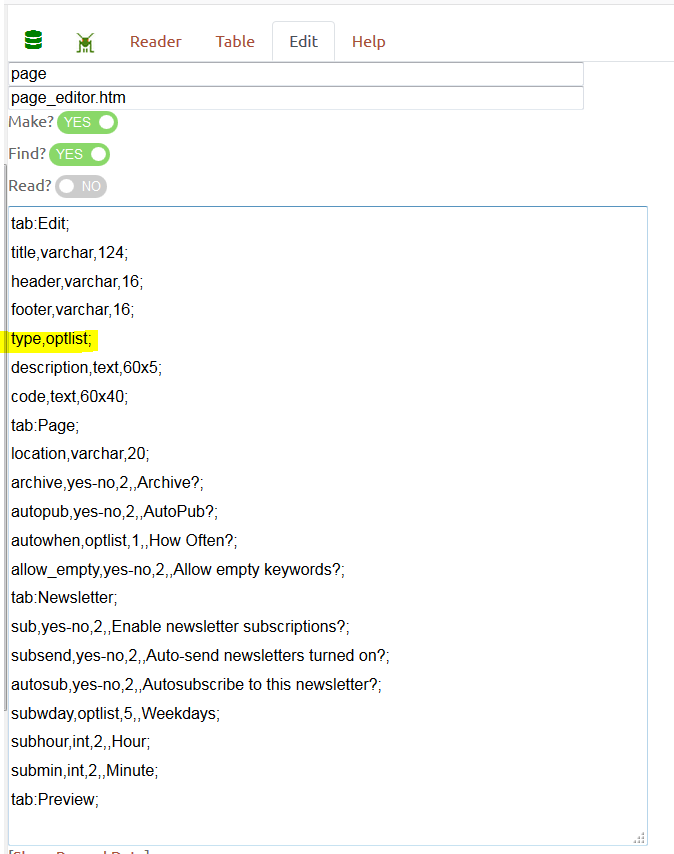 |
| Figure 107 - page in the Form Editor, addition of 'type' highlighted |
And the revised Page Editor with the page type selection (you can see I've selected XML):
 |
| Figure 108 - Page Editor with page type XML selected |
It's important to test XML file output, especially when it's created in a relatively loose fashion this way. The original OPML validator is no longer responding to requests, but I used the OPML viewer to validate. Here's what it looks like:
 |
| Figure 109 - OPML Viewer |
I stopped work and made a couple of videos related to this:
Using OPML - https://www.youtube.com/watch?v=1NNLU10VitQ
Harvesting Feeds on gRSShopper: https://www.youtube.com/watch?v=e1pK-rQeAI4
JSON
While I'm working on the feeds list I'll export in JSON as well. Again, I could use a Perl module specifically designed for this, and in some cases I will. But for something quick and custom, we can just create a JSON page.
It's the same process as before. I'll make my Course Feeds JSON page, using json as the output format. I'll also include the header information right in the page.
First I'll create the page:
 | |||
| Figure 11- Course Feeds JSON page in the Page Editor |
Next I'll create a feed_json view
 |
| Figure 111 - feed_jsonpost view in the View Editor |
Notice the use of a keylist in the feed_json view. This will embed a list of one or more authors in the JSON outpit. So I need a JSON view for the author. Since it's a small one-liner I'll give it a specially named view: feed_jsonpost (that way, I'l reserving the author_json view for a full page view).
Here it is:
 |
| Figure 112 - author_jsonpost view in the View Editor |
Notice there's no comma after this view, and there was one in the earlier view. This actually matters; I don't know why, but the parsers rejected a list (inside []) with a comma after the last item. So, go figure (took me an hour to work this out).
Now I'll publish the page and view it in the browser:
 |
| Figure 113 - JSON page in Firefox |
 |
| Figure 114 - JSON page in Chrome |
Now right now there's no way for a harvester to know whether it's harvesting posts or feeds. As I develop gRSShopper I'm going to need to make this clear, because I intend to share all kinds of data, not just posts. So I'll introduce a new data element for the header, which I'll call 'datatype'. It states what table the JSON came from in gRSShopper. There will be no obligation for other sites to store this data as feeds, but it's a suggestion.
I'll add that to the page now, so you can see it:
 |
| Figure 115 - Course Feeds JSON Page in the Page Editor with new 'datatype' value highlighted |
 |
| Figure 116 - JSON validated in the JSON validator |
That's it for the feeds list. We'll use this more in the future. But next we need to make RSS out of our Newsletter page so we can set it up for automatuic emailling by MailChimp. So I'll close out this post and start a new one.
%20LinkedIn.png)
Comments
Post a Comment
Your comments will be moderated. Sorry, but it's not a nice world out there.