Reimaging Open Educational Resources
This is an edited transcript of my presentation 'Reimaging Open Educational Resources' presented November 10 2020 to the Open Education 2020 Conferemce. https://www.downes.ca/presentation/534

So what I want to talk to you today talked about with you today is open education resources. I'm going to talk about content addressable open education resources and some of the mechanisms we can use to create and store and use OERs in a new post-licensing fashion (it's maybe not the best way to put it, but...)
After this session you'll be able to talk about how content addressing works. You'll be able to explain it to your children. That's my plan. You'll be able to talk about the use of content addressing to enable a secure and distributed resource network, to create and add your own resources to this network, to access and reuse these, and to appreciate how this approach might offer an alternative to open educational resources as we currently know them.
You know, there are issues right now with Open Educational Resources (OERs - I don't want to stumble over that the whole session) significant enough that Creative Commons has issued a new Creative Commons strategy. They're on their second draft and they're saying things like "the licenses do not address mainstream content sharing" and "the licenses are not fully addressing collateral damage by exploitative decontextualized use and reuse of shared content."
And we've seen some of that in education where the content including open educational content is being amassed in centralized repositories, people are putting walls around them, even when we use them in a university you may end up having to pay tuition in order to access the content management system, etc. None of this feels properly open to me and I think none of it feels properly open to anyone else now.
I know not everybody wants to hear tech talk. I get that. And I'm not going to say that tech talk will solve the whole thing, but I invite you to rethink how we go about doing Open Educational Resources, and if we have this rethink, we can begin to think creatively of alternatives to how we do it today.
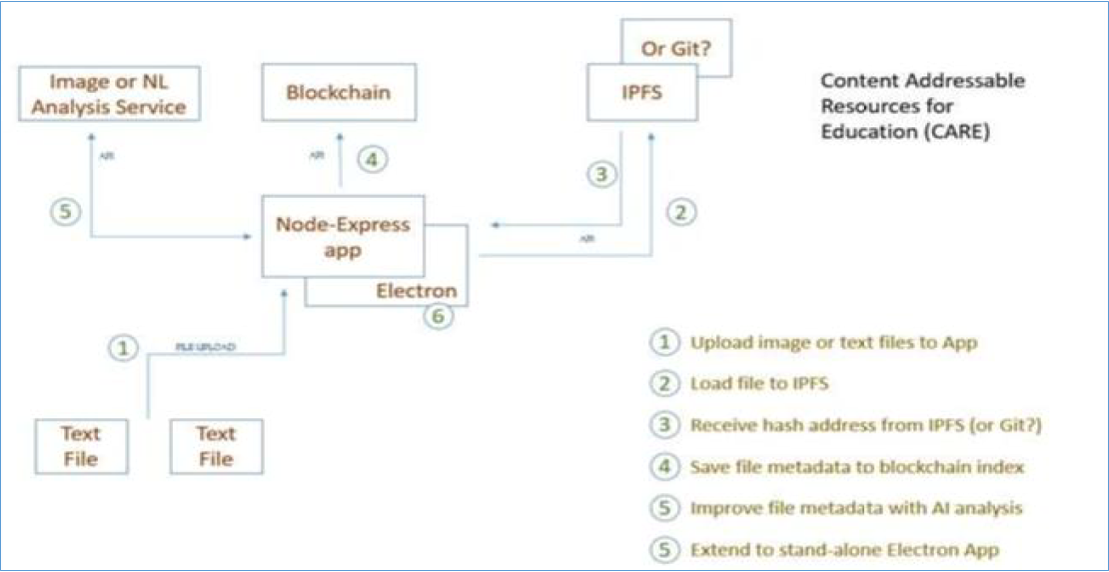
So what I did a couple years ago now is to create something called Content Addressable Resources for Education. I've run this through a couple of trial so far, one in a course, and then another in a summer project with a student (Rashi Nagpal) building systems that create these Content Addressable Resources for Resources for Education or care (as an aside, I came up with this before the whole 'duty of care' and 'care and education' and 'care and openness' became a big thing; it's a complete coincidence).
Now let's begin. I'm going to begin with encryption algorithms. I know that slide is a mess, don't worry about it, you don't need to remember any of the details of it. I just put it there for completeness. You can go to the Wikipedia page and find more details. What I want you to see is there is a bunch of encryption algorithms and what they do is they take content, whatever the content is, they run it through an algorithm using operations like and 'xor', 'rot' (which is rotate), 'add', etc. and create an output that is an encryption of the resource. So you can dig into these ad nauseam if you wish but you don't need to.
So there are different kinds of encryption, the kind of encryption that as kids maybe we used for to send codes back and forth, or two way encryptions, right? I encode the message. I send it to you. You decode the message. You read it. The (Enigma) encoder that was decoded by Alan Turing during the Second World War was one of these kind of things.
On the other hand, you might have one-way encryption. That's where you take the content you run it through the algorithm you get a string, a scrambled string of characters, called a hash, and when you have that hash, you can't go back the other way. You can't figure out what the original string was. That's the kind of encryption that we're going to use. We're going to use one-way encryption.
So we take the content, run it through the hash, and get this random string of characters. Your children are understanding that so far, no problem. All right, now what's neat about this is if we use a long enough algorithm, we can have a unique string of characters for each individual content.
So here's an example. My original content was "Come on over" and I got my hash. And then I added a word. I said "Come on over now." Adding that word creates a new unique hash. Now, we can have hundreds of millions, billions, trillions, of hash combinations, which means that you can take something like the novel "War and Peace", run it through one of these algorithms, get a string of a certain length as your hash, and if you change one comma somewhere in "War and Peace", you get a new hash a different hash. So far so good. Of course I'm hearing the cheers in the hallways.
Right now, here's the neat trick. This is the thing that makes it all work. What we're going to do is instead of using the location of a file like, you know, http://www.downes.ca points to a certain specific server on the internet, instead of using that as the URL, we're going to create a content-based address for that URL.
So what we're going to do is we're going to take our content, we're going to create a new hash out of that content, and so out of all of that we're going to create a new kind of like URL. We'll use the dat:// protocol in this case (there are different protocols but that is very common). The prefix will in some way point to the algorithm that we're using. That way whoever receives it will know what algorithm to use or what algorithm was used in order to create the hash. And then the second part of that is the hash itself. So the hash of the content becomes the address. Hence 'content based addressing'.
Now what's neat about this is we can join these hashes together to create chains of resources, for example, revisions. Remember. I started with 'Come on over' as my first version, and then 'Come on over now' was my second version. Each of these had their own unique hashes. Let's take those two hashes combine them together and hash that. Now we have a hash that represents the combination of these two hashes. It's almost like a little tree, isn't it? But it's a way of linking these resources together to form what they call a graph - a hashgraph.

Makes sense, right? So one type of hash graph, and the type that's used most commonly is called a Merkle chain. So here's a Merkle chain you can see a bunch of items TA, TB, TC, TD, etc. on the bottom row, we've got hashes of each of these HA, HB, etc, and then we have the combination HAB, HCD, etc, and then we combine the combinations, and we create one big graph out of all of that.
So one site or service, you may have heard about it, is Git or GitHub. This is the internationally well-known source code repository for open source software. It uses Merkle chains, in other words, it uses a hash graph. These are actually widely used on the internet. You don't see them, but they're widely used. They're used in different file systems like Interplanetary File System, the dat:// protocol we just talked about, Apache wave protocol, Git and Mercurial revision control systems, the Bitcoin and Ethereum blockchain networks, and no-SQL databases such as Cassandra and Dynamo, and many other things.
So this is already forming a base layer for the internet that is not based on location. It's based on hash. And actually if you go around when you when you're browsing through the internet, maybe reading an article, it's some magazine or whatever, have a look at the URL at the top of the page, and if you see a long string of nonsense characters, that's probably a hash.

So, how do we make this work for education? How do we create content addressable resources for education? Well, we set up a network, a peer-to-peer network, not a hub-and-spoke where you have one big whacking index or one gigantic server like Facebook or whatever. No. A network where you connect to other people other people connect to you. Some nodes or servers on this network are big. Some of them are small. They each connect to some but not all of the network. So: distributed. There are all kinds of reasons why this is a better way to set up the network, which I can't go into in a short session like this.
Anyhow set up a network like that. So, each node in the network, including your node, each node in the network stores only the content that it's interested in, and some indexing information just to help find other resources on the distributed network. Now when you access this network to find a resource you use the content addressable address, right? Use that hash, and you put it in a request on the network. You ask the node nearest to you if they have it. If they don't they'll just pass your request along. Somebody will eventually have it, and then they just send it directly to you. That's how it works.
So what's really neat about this is I can store these resources anywhere. It doesn't have to be in a certain spot. I can store multiple copies of this resource and nobody can take this resource and lock it behind a paywall, a subscription wall, a spam wall, a learning management system, value added services, anything like that. It's always going to be available directly from the distributed peer-to-peer network. That ensures that our Open Educational Resources are open.
All right. We can also be sure that the resources are secure. I make a request and some random node out there has the resource. They send it to me, and now I'm wondering, did they send me the real resource or a fake version? Well, it's easy for me to check. I take what they sent me. I run it through the proper algorithm and I get a hash. That hash should match the address that I first used. If I match the address I know that my resource is the original,down to the last comma,that I was looking for. If any change has been made to it at all then the hashes won't match, and I'll know that I was sent a fake.
So think about this. Think about the range of applications possible for you. You could use them for learner generated content, activity records, digital badges. They are private and secure. You can determine for yourself or participants can determine for themselves what they're going to share.
And you know, if you think about it, normally we think the course is just going to be on one server, but we're going to distributed file sharing network, so the course is on any number of servers. The instructor's on a server, each individual participant in the course is on a server, everybody's deciding for themselves what they want to share, what they want to store, and how they're going to view it.
So as I said I've been messing around with this. I recently developed and use some of these resources in a MOOC. I have demo stuff here, but there's utterly no time to be able to show it to you, but a lot of this is on my website. Here's the course itself that I messed around with a lot of this stuff in, the eLearning 3.0 course. I offered it first about two years ago, and I'll offer it again in the future, this is the address (the old-style address because I want to make sure you can get to it): https://el30.mooc.ca

The idea here is that the course isn't you know, like a book or a magazine or anything like that. The course is a web of distributed data and we can connect this web of distributed data using these Merkel graphs and what's really cool is we can take things from the instructor of the course, transcripts from Hangouts, competency definitions, even contributions by authors and other resources that other people contribute, add them all to this graph as much as we want. We can even create badges and store them on the blockchain.
So the course can be this dynamic this fluid thing that you can access any part of, all parts of, really, it's up to you, and have different kinds of resources, not just text, not just a 'learning resource' but actual software scripts, JavaScript applications, whatever.
Here's an IPFS desktop, and the URL at the bottom there you can install one for yourself here. I'm connected to a hundred and ninety nine peers. I'm sharing files with them, they're sharing files with me and we're in this peer-to-peer network. This might not be the whole network this is just what I'm connected to; it's kind of like the tip of a much larger iceberg.
You browse in the IPFS network in different ways. One way, for example is to use the IPFS web hub so that way if you use this prefix https://ipfs.io/ipfs then any resource hash that you put in after that you'll be able to see that resource. Also you can put plugins into a browser like a Firefox browser or a Brave browser. Brave is a browser that's built natively for this kind of distributed network it uses IPFS protocol content, you can install it from brave.com.
The Interplanetary File System has a range of resources and services, everything from collaboration to prediction to marketplaces to wikis to all kinds of stuff. There's really no shortage because again anything can be content addressable, including software applications. In fact, if you download an application off the internet, one of the things that happens behind the scene is they run a hash to verify that your download wasn't disrupted by what they call a "man in the middle" so that you know you're getting the application that you signed on for and not something from Russia.
I know this has been a fast and furious presentation. I'll stop the presentation here,but that basically is the idea.
%20LinkedIn.png)
This comment has been removed by a blog administrator.
ReplyDeleteThis comment has been removed by a blog administrator.
ReplyDelete